
生成AIを使っているとき、「2025年の最新ニュースについて教えて」と質問して、事実とは異なるもっともらしい回答が返ってきた経験はないでしょうか。
あるいは「自社の社内規定について答えてほしい」と思っても、AIがその中身を知らなすぎるために活用を断念したことはないでしょうか。
現在の生成AI(大規模言語モデル:LLM)には、学習したデータが古い、あるいは特定の組織内の情報を知らないという構造的な課題があります。
この課題を解決し、AIの回答精度を飛躍的に高める技術として注目されているのが「RAG(ラグ)」です。
この記事では、RAGがどのような仕組みで動き、私たちの情報収集や業務をどう変えるのか、客観的な事実に基づいて解説します。
なぜAIは「知らないこと」を答えてしまうのか
まず前提として、ChatGPTやGeminiなどのAIは、あらかじめ膨大なインターネット上のデータを学習しています。
しかし、その学習には膨大な時間とコストがかかるため、頻繁に更新することが困難です。
その結果、以下の2つの問題が発生します。
- 情報の鮮度不足:
学習が完了した後の出来事(昨日のニュースや新製品情報など)を知らない。 - 専門・内部情報の欠如:
一般に公開されていない社内マニュアルや個人のメモ、特定の業界の最新論文などを把握していない。
このような状況でAIに質問をすると、AIは手持ちの古い知識を組み合わせて「それらしい嘘」をついてしまうことがあります。
これが「ハルシネーション(幻覚)」と呼ばれる現象です。
ハルシネーションについて詳しく知りたい方は、こちらの記事でその原因と対策を確認してみてください。

RAG(検索拡張生成)の仕組み
RAGとは、Retrieval-Augmented Generationの略称です。
直訳すると「検索により強化された生成」となります。
従来のAIが「自分の記憶(学習データ)だけで答える」のに対し、RAGは「回答する直前に、関連する信頼できる資料を検索して読み、その内容を要約して答える」というステップを踏みます。
具体的なプロセスは以下の通りです。
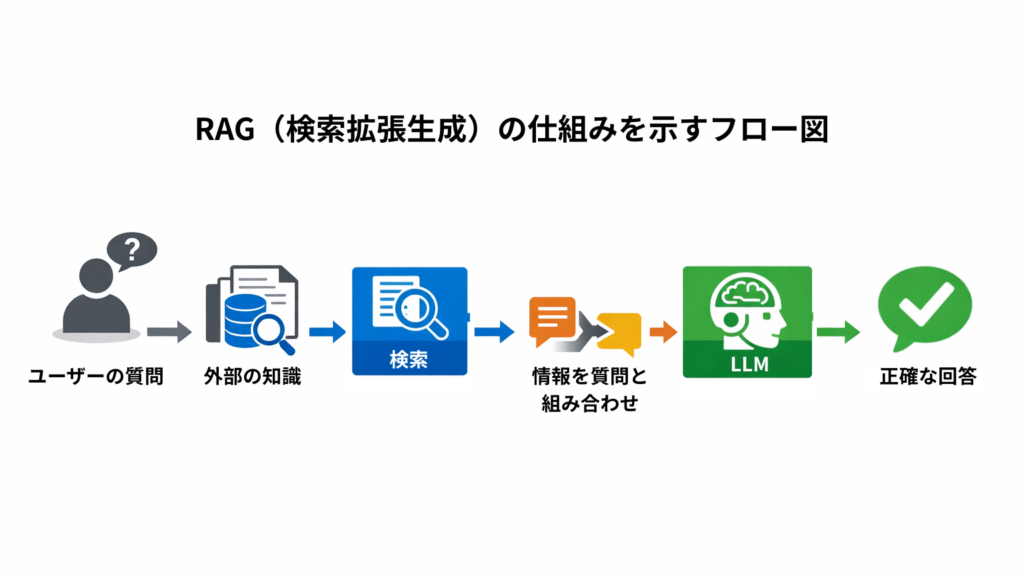
- ユーザーの質問:
利用者がAIに質問を投げかけます。 - 情報の検索(Retrieval):
質問に関連するキーワードや意味を元に、外部のデータベースやPDFファイルなどから必要な情報を探し出します。 - 情報の追加(Augmented):
探し出した情報の断片を、元の質問と一緒にAIに渡します。 - 回答の生成(Generation):
AIは渡された資料を「根拠」として読み、正確な回答を作成します。
この仕組みにより、AIは「自分の知らないこと」でも、その場で資料を参照することで正確に回答できるようになります。
自分専用の資料を読み込ませて活用するツールとしては、Googleの「NotebookLM」が有名です。以下の記事でその具体的な機能を解説しています。
RAGを導入する3つのメリット
RAGを活用することで、従来のAI利用にはなかった大きなメリットが得られます。
回答の正確性と信頼性の向上
AIが独自の判断で答えるのではなく、指定された資料(ソース)に基づいて回答するため、ハルシネーションを劇的に抑制できます。
また、多くのRAGシステムでは「どの資料のどの部分を参考にしたか」という参照元(出典)を表示できるため、人間が後から事実確認を行うのが容易になります。
最新情報の即時反映
AI本体を再学習(ファインチューニング)させるには数週間から数ヶ月の期間と多額の費用がかかりますが、RAGであれば参照先のデータを更新するだけで済みます。
例えば、ニュースサイトの記事を検索対象に含めれば、公開されたばかりの情報についてもAIが参照して回答できるようになります。
セキュリティとプライバシーの確保
機密性の高い社内文書をAIモデルそのものに学習させてしまうと、他の利用者にその情報が漏洩するリスクがあります。
しかしRAGの場合、データは組織が管理する安全なサーバー(データベース)に置いたまま、回答時に一時的に参照するだけなので、情報漏洩のリスクを管理しやすくなります。
AIを利用する際のプライバシー設定については、以下の記事も参考にしてください。
2026年現在のRAGを取り巻く状況
2026年現在、RAGは単なる「テキスト検索」から、より高度な「マルチモーダルRAG」へと進化しています。
以前はテキストデータのみが対象でしたが、現在は図表が含まれるPDF、プレゼンテーションスライド、さらには動画や音声データの中から必要なシーンを検索し、それらを組み合わせて回答を生成することが可能になっています。
また、企業での導入も一般化しており、カスタマーサポートの自動応答や、社内規定の検索、技術ドキュメントの要約など、特定の知識が必要な場面ではRAGが不可欠な技術となっています。
画像や音声など、複数の情報を扱う「マルチモーダル」の仕組みについてはこちらで解説しています。
FAQ:よくある質問
- QRAGを使えば、AIは絶対に嘘をつきませんか?
- A
100%防げるわけではありません。
参照した資料自体に誤りがある場合や、AIが資料を読み間違える可能性はゼロではないため、重要な判断には人間による最終確認が必要です。
ただし、従来のAI単体での回答に比べれば、正確性は格段に向上します。
- QRAGと「ファインチューニング(追加学習)」は何が違うのですか?
- A
RAGは「辞書を引いて答える」仕組み、ファインチューニングは「AIの脳そのものを書き換えて暗記させる」仕組みです。
特定の口調や専門的な言い回しを覚えさせたい場合は学習(ファインチューニング)が向いていますが、事実情報を最新に保ちたい場合はRAGが適しています。
- Q個人でもRAGを利用できますか?
- A
はい、可能です。Googleの『NotebookLM』や、ChatGPTでファイルを読み込んで対話できる機能、特定のPDFを扱うWebサービスなど、プログラミング知識がなくてもRAGの仕組みを体験できるツールが増えています。
まとめ:RAGはAIを「実用的」にする鍵
RAG(検索拡張生成)は、AIの最大の弱点であった「情報の古さ」と「不正確さ」を克服するための現実的な解決策です。
- 検索(Retrieval):信頼できる外部データから探す。
- 拡張(Augmented):質問に資料を添える。
- 生成(Generation):根拠に基づいて回答を作る。
このプロセスによって、AIは単なる「お喋りな知能」から、特定の専門知識や最新情報を正確に扱う「実務的なパートナー」へと進化しました。
今後、私たちが触れるAIサービスの多くには、このRAGの仕組みが標準的に組み込まれていくことになるでしょう。
まずは、身近なドキュメントを読み込ませて対話できるツールから、その精度の高さを体験してみてはいかがでしょうか。