
「最近のAIはすごい」と聞くけれど具体的に何がそんなに進化しているのか、いまいちピンとこないことはありませんか?
これまでのAIは「文章を書くのが得意」「画像を見分けるのが得意」といったように、一つのことだけに特化しているものがほとんどでした。
しかし、今まさに注目を浴びている「マルチモーダル(Multimodal)」という技術は、その常識を根底から覆そうとしています。
簡単に言えば、AIがテキストだけでなく、画像・音声・動画を同時に理解し、状況に合わせて答えられるようになってきているのです。
今回は、知っているようで知らない「マルチモーダル」の正体と、それが私たちの日常をどう変えていくのかを、5分で読める内容にまとめてお届けします。
そもそも「マルチモーダル」って何?
「マルチモーダル」という言葉を分解すると、2つの意味が見えてきます。
- マルチ(Multi): 複数の、多様な
- モーダル(Modal / Modality): 形式、様式(情報の種類)
つまり、「複数の種類の情報を組み合わせて処理する仕組み」のことです。
AIの世界における「情報の種類(モード)」には、主に以下のようなものがあります。
- テキスト(文字情報)
- ビジョン(画像・動画情報)
- オーディオ(音声・音楽情報)
- センサーデータ(温度や位置情報など)
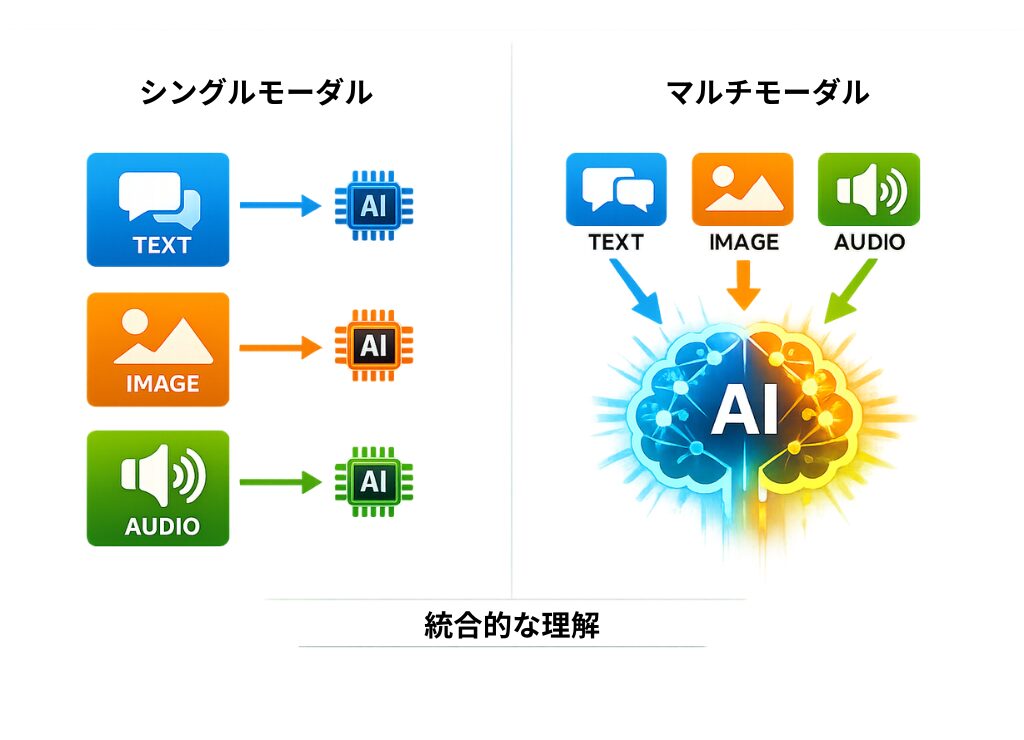
これらをバラバラに扱うのではなく、「同時に、関連付けて」理解できるのがマルチモーダルAIの最大の特徴です。
なぜ「マルチモーダル」は革命的なのか
これまでのAIと何が違うのか、具体的な例で考えてみましょう。
例えば、あなたが冷蔵庫の中にある「使い道に困った野菜」の写真をAIに見せたとします。
- これまでのAI(シングルモーダル):
「これはキャベツです」「これは人参です」と、画像の内容を当てるだけでした。 - これからのAI(マルチモーダル):
画像から「キャベツと人参」を認識し、あなたの「これで作れるレシピを教えて」というテキスト(言葉)の意図を汲み取り、最適な料理法を提案してくれます。
さらに、料理の工程を「動画」で見せれば、AIは「今、少し火が強すぎますよ」と視覚と時間の経過を考慮したアドバイスをくれることさえ可能になります。
このように複数の情報を組み合わせることで、AIはより「文脈(コンテキスト)」を深く理解できるようになったのです。
AIが文脈を理解することの重要性については、こちらの記事でも詳しく触れています。あわせて読むと理解がより深まります。

私たちの生活はどう変わる?
マルチモーダル技術の進化によって、AIは単なる「検索ツール」から「有能なパートナー」へと進化しています。
視覚障害者の方の「目」になる
スマートフォンで周囲を映すと、AIが「今、目の前の信号が青になりました」「左側にベンチがあります」と音声で状況を伝えてくれます。
文字だけでなく、空間そのものを理解できるからこそ可能になった技術です。
学習や仕事の効率が劇的に上がる
教科書の図解を指差して「ここがわからない」と聞けば、AIがその図の内容を瞬時に読み取り、音声やテキストで解説してくれます。
また、会議の動画を読み込ませて「議論が紛糾したのはどのあたり?」と聞けば、映像と音声から該当箇所を探し出してくれるようになります。
より「人間らしい」コミュニケーション
AIはユーザーの表情(画像)や声のトーン(音声)から、その時の感情を推測できるようになります。
落ち込んでいる時には励ますような言葉を選び、急いでいる時には簡潔に答えるといった、相手に合わせた柔軟な対応が可能になります。
主要なマルチモーダルAIの例
現在、私たちが手軽に触れられるマルチモーダルAIには以下のようなものがあります。
- Gemini(Google):
Googleが開発したAI。テキスト、画像、音声、動画をネイティブに扱えるよう設計されており、特に動画の解析能力に定評があります。 - GPT-4o(OpenAI):
「o」は「Omni(オムニ:あらゆる)」を意味し、リアルタイムでの音声対話や画像理解が非常にスムーズです。
それぞれの特徴や詳しい使い分けについては、以下の比較記事を参考にしてみてください。
よくある質問(FAQ)
- Qマルチモーダルを使うには、特別な機械が必要ですか?
- A
いいえ、今お使いのスマートフォンやPCから、ブラウザやアプリを通じて利用できます。
カメラやマイクがついているデバイスであれば、その場でマルチモーダルな体験が可能です。
- Q写真を送るとプライバシーが心配です。
- A
非常に重要な視点です。AIに送信したデータが学習に利用される設定になっている場合があります。重要なプライバシー情報を含む画像などは、設定を確認してから送るようにしましょう。
- Q動画も理解できるって本当ですか?
- A
はい、可能です。例えば数十分の動画をアップロードして「この動画で一番盛り上がっているシーンを要約して」といった指示を出すことができます。
まとめ:AIは「知識」から「体験」のフェーズへ
マルチモーダルとは、AIがテキストという「言葉」の壁を超えて、画像や音声といった「現実世界のあらゆる情報」を扱えるようになる技術のことです。
これまでのAIが「物知りな辞書」だったとするならば、マルチモーダル化したAIは「一緒に世界を見て、聞いてくれるパートナー」に近い存在だと言えるでしょう。
「何ができるか」を理屈で考えるよりも、まずは身近な写真をAIに見せて「これについて教えて」と話しかけてみるのが、マルチモーダルを理解する一番の近道かもしれません。