
最近、スマートフォンの顔認証や、驚くほど自然な自動翻訳など、AIの進化を肌で感じる機会が増えました。
これらの高度な処理を裏側で支えているのが「ニューラルネットワーク」という技術です。
言葉だけを聞くと難しそうに感じますが、その考え方は私たちの「脳」をお手本にしています。
人間が経験を通じて物事を覚えるように、コンピュータもまた、網の目のように張り巡らされたネットワークを通じて情報を処理し学習していきます。
この記事では、AIがどのようにして知的な判断を下しているのか、その核心部分であるニューラルネットワークの仕組みを順を追って整理していきます。
ニューラルネットワークは「脳の仕組み」の模倣
ニューラルネットワークとは、人間の脳にある神経細胞「ニューロン」の働きを数式を用いてコンピュータ上で再現しようとしたモデルのことです。
私たちの脳では、無数のニューロンが電気信号をやり取りすることで「これはリンゴだ」「これは椅子だ」といった判断を行っています。
AIの世界でもこれと同じように、情報を伝達するユニットをいくつも繋げ、それらが連携することで複雑な計算を実現しています。
3つの階層構造
ニューラルネットワークは、大きく分けて以下の3つの層で構成されています。
- 入力層:
外部からのデータ(画像やテキストなど)を受け取る最初の窓口です。 - 隠れ層(中間層):
入力された情報を加工・分析する層です。ここで「特徴」を抽出します。 - 出力層:
最終的な判断結果(「これは猫です」といった答え)を出す層です。
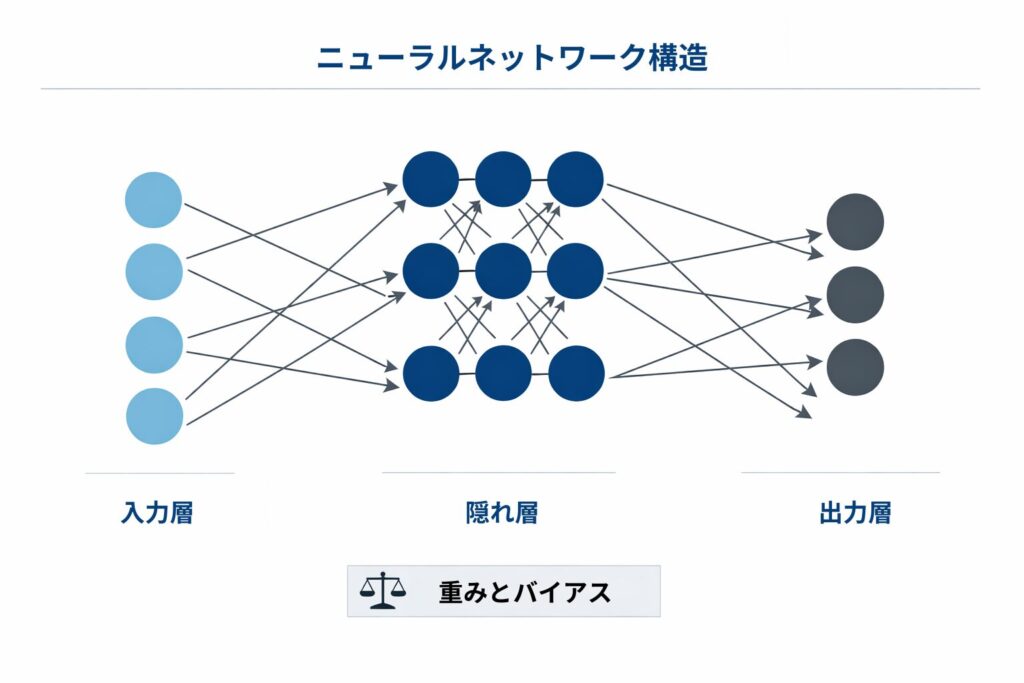
この仕組みによって、コンピュータは単なる計算機を超えた、パターン認識のような「柔軟な判断」ができるようになります。
より根本的な「コンピュータが学習するプロセス」については、こちらの記事で詳しく紹介しています。
コンピュータが自らルールを見つけ出す「機械学習」の全体像については、以下の記事で解説しています。

どうやって「学習」しているのか?
ニューラルネットワークが賢くなるプロセスには、「重み」という数値の設定が欠かせません。
この数値を調整する作業こそが「学習」の正体です。
- 順方向(予測):
まず、入力されたデータに現在の「重み」を掛け合わせながら、入り口から出口へと計算を進めます。
これを「順伝播(じゅんでんぱ)」と呼び、最終的な答え(予測値)を出します。 - 誤差の算出:
出た答えと、あらかじめ用意された「正解」を比較します。
このとき発生したズレを「誤差」として数値化します。 - 逆方向(修正):
算出された「誤差」を減らすために、今度は出口から入り口に向かって「どの重みが、どれくらい間違いの原因になったか」を逆順に計算していきます。
これを「誤差逆伝播法(バックプロパゲーション)」と呼びます。
出力結果と正解の誤差を計算し、その誤差を逆方向に伝えて重みを修正する(誤差逆伝播法)ことで精度を高めていきます。
具体的には、出口に近い層から順番に「この数値(重み)を少し減らせば、誤差が小さくなる」という修正の方向と量を計算し、それをバケツリレーのように入り口側の層へと伝えていく仕組みです。
ディープラーニング(深層学習)との決定的な違い
よく耳にする「ディープラーニング」という言葉。
実は、これもニューラルネットワークの一種です。
最大の違いは、先ほど説明した「隠れ層」の数にあります。
層の「深さ」が知能を変える
従来のニューラルネットワークは、隠れ層が1層〜数層程度のシンプルなものでした。
これに対し、隠れ層を数十層、あるいは数百層と「深く」積み重ねたものがディープラーニングです。
- 従来のモデル:
構造が単純なため、複雑なデータの判別には限界がある。 - ディープラーニング:
層が深いため、非常に細かな特徴まで捉えることができる。
ディープラーニングが具体的にどのような可能性を秘めているのか、こちらの記事でさらに深く掘り下げています。
人間の手助けがいらなくなる
もう一つの大きな違いは、AIが「どこに注目すべきか」を自分で見つけられるかどうかです。
従来の機械学習では、「耳の形に注目してね」と人間がヒント(特徴量)を与える必要がありました。
しかし、ディープラーニングは大量のデータを読み込むうちに、AI自身が「この部分が判別の決め手だ」と自動で学習します。
この「学習の自動化」が、現代のAIの驚異的な進化を支えています。
身近な場所で活躍するニューラルネットワーク
この技術は、すでに私たちの生活のいたるところで使われています。
- 画像認識:
スマートフォンのアルバムで「人物」ごとに自動で仕分けされる機能や、車の自動ブレーキシステム。 - 音声認識:
スマートスピーカーが私たちの声を聴き取り、指示を理解する仕組み。 - 自然言語処理:
Google翻訳などの精度の高い翻訳や、ChatGPTのような対話型AI。
特にChatGPTなどの「会話ができるAI」の背景には、このネットワークをさらに巨大化させた「LLM(大規模言語モデル)」という技術が関わっています。
会話型AIの心臓部である「LLM」の仕組みについては、こちらの記事で優しく解説しています。
FAQ:よくある疑問
- Qニューラルネットワークを学べば、AIを作れるようになりますか?
- A
基本的な仕組みを理解することは、プログラミングやデータ分析を学ぶための強力な土台になります。
最近ではPythonなどの言語を使って、初心者でもライブラリを利用してモデルを構築することが可能になっています。
- Qなぜ最近になって急に注目されるようになったのですか?
- A
「膨大なデータ(ビッグデータ)」と「高性能な計算機(GPU)」が手に入るようになったからです。
理論自体は数十年前からありましたが、それを実行するための環境が整ったのが、近年のAIブームの要因です。
- Qニューラルネットワークに弱点はありますか?
- A
「なぜその答えを出したのか」というプロセスが人間にはブラックボックスになりやすい点や、学習に膨大な電力と時間が必要な点が挙げられます。
まとめ:AIの思考を支えるインフラ
ニューラルネットワークは、人間の脳の仕組みをヒントに生まれた、AIの「思考のインフラ」とも言える技術です。
- 入力層・隠れ層・出力層の3層構造が基本。
- 重みの調整と誤差の修正を繰り返すことで学習する。
- 層を深くしたものがディープラーニングであり、現代AIの主役である。
これまでは「コンピュータは言われたことしかできない」と思われてきましたが、このネットワークのおかげで、AIは自らルールを見つけ、私たちを驚かせるような答えを出せるようになりました。
次にAIに触れるときは、その裏側で無数の「ニューロン」が電気信号のように情報を処理している姿を想像してみると、少し違った景色が見えるかもしれません。